
7月买球下单平台,OpenAI尚未按照此前筹划发布GPT-5,智能体方面的更新先行面世了。
北京时辰7月18日凌晨,OpenAI直播发布了ChatGPT Agent,这一智能体交融了Operator智能体网页交互智力以及Deep Research功能,使ChatGPT内置筹画机能匡助用户完成复杂的多智商任务。
“面前ChatGPT不错念念考和活动,能主动从手段器用箱中遴荐器用,完成一些任务。”OpenAI先容,这些任务包括“寻查我的日期并凭证近期新闻先容行将举行的会议”“分析三个竞争敌手并创建幻灯片”等。此外,用户还不错实行一些重迭任务,举例将屏幕截图转机为可裁剪PPT、用新的财务数据更新电子表格、再行安排会议。
据先容,ChatGPT的责任进程包括浏览网站、过滤恶果、辅导用户登录关系账号、运行账号、分析、创建电子表格和幻灯片。
此前OpenAI曾单独发布Operator和Deep Research功能,其中Operator亦然一个智能体,不错迁徙、点击网页,帮用户完成餐厅预订等任务,Deep Research则主要面向信息深度分析和整合任务。OpenAI称,这次ChatGPT的中枢更新是创建了一个协调的智能体系统,使Operator调遣网站的智力、Deep Research整合信息的智力、ChatGPT对话智力情投意合。这次发布的智能体系统不错调用可视化浏览器、文本浏览器、终局器用、API接口,差别可用于与网页交互、惩处无数文本、运行代码或下载文献、访谒GitHub等哄骗数据。
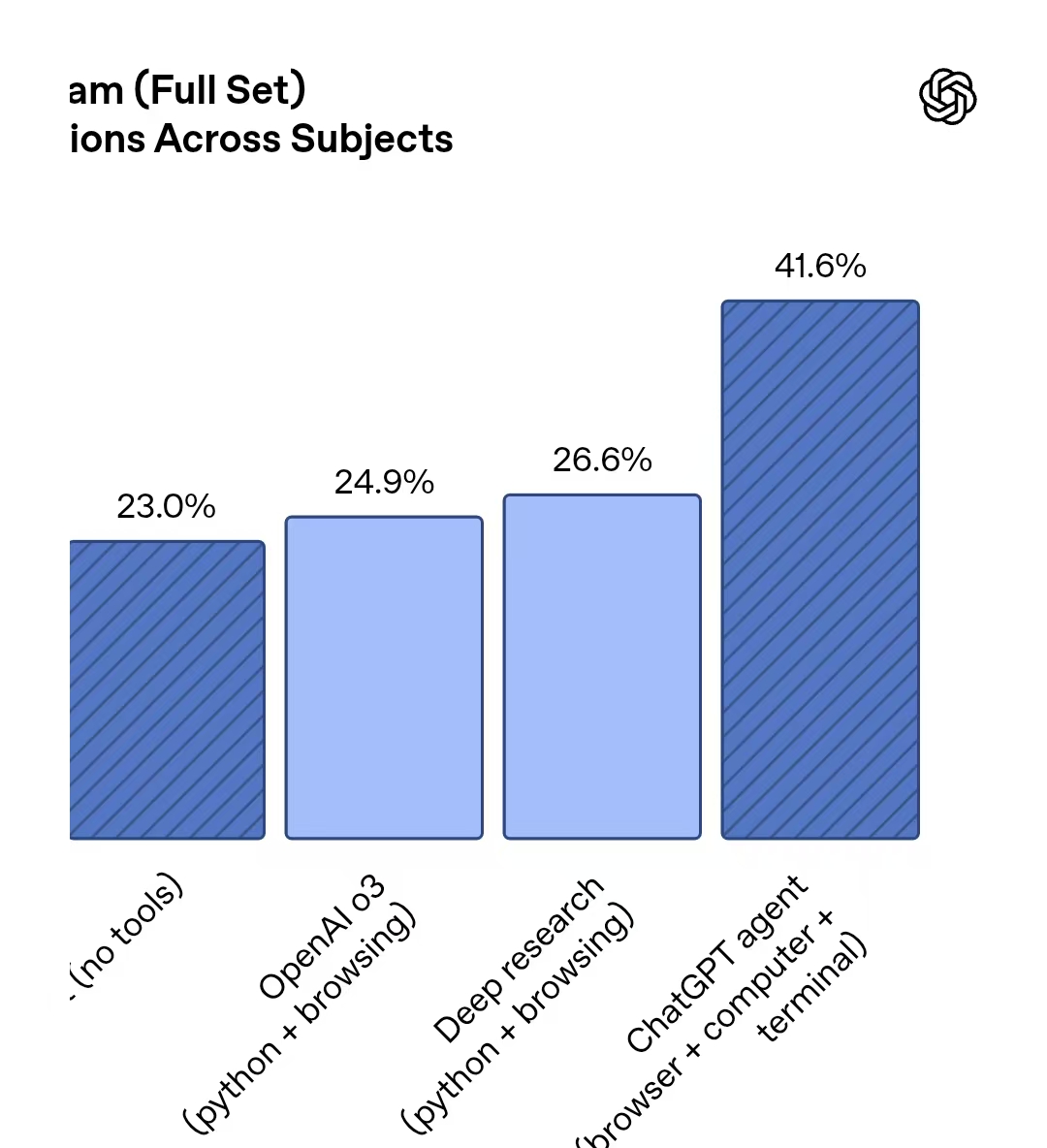
从基准测试发挥看,在跨学科内行级测试Humanity’s Last Exam中,ChatGPT Agent回报准确率为41.6%,朝上Deep Research的26.6%、o3模子的24.9%;在数学基准测试FrontierMath中,ChatGPT Agent准确率为27.4%,高于o4 mini的19.3%和o3的10.3%;在针对着实学问责任任务的里面评测中,ChatGPT Agent在约半数案例中的发挥与东谈主类抓平或朝上东谈主类;在实践数据科学任务DSBench测试中,ChatGPT的分析与建模准确率差别为89.9%和85.5%,朝上东谈主类水平;在掂量模子承担一到三年投资银行分析师建模任务智力的里面基准上,准确率高于o3和Deep Research。
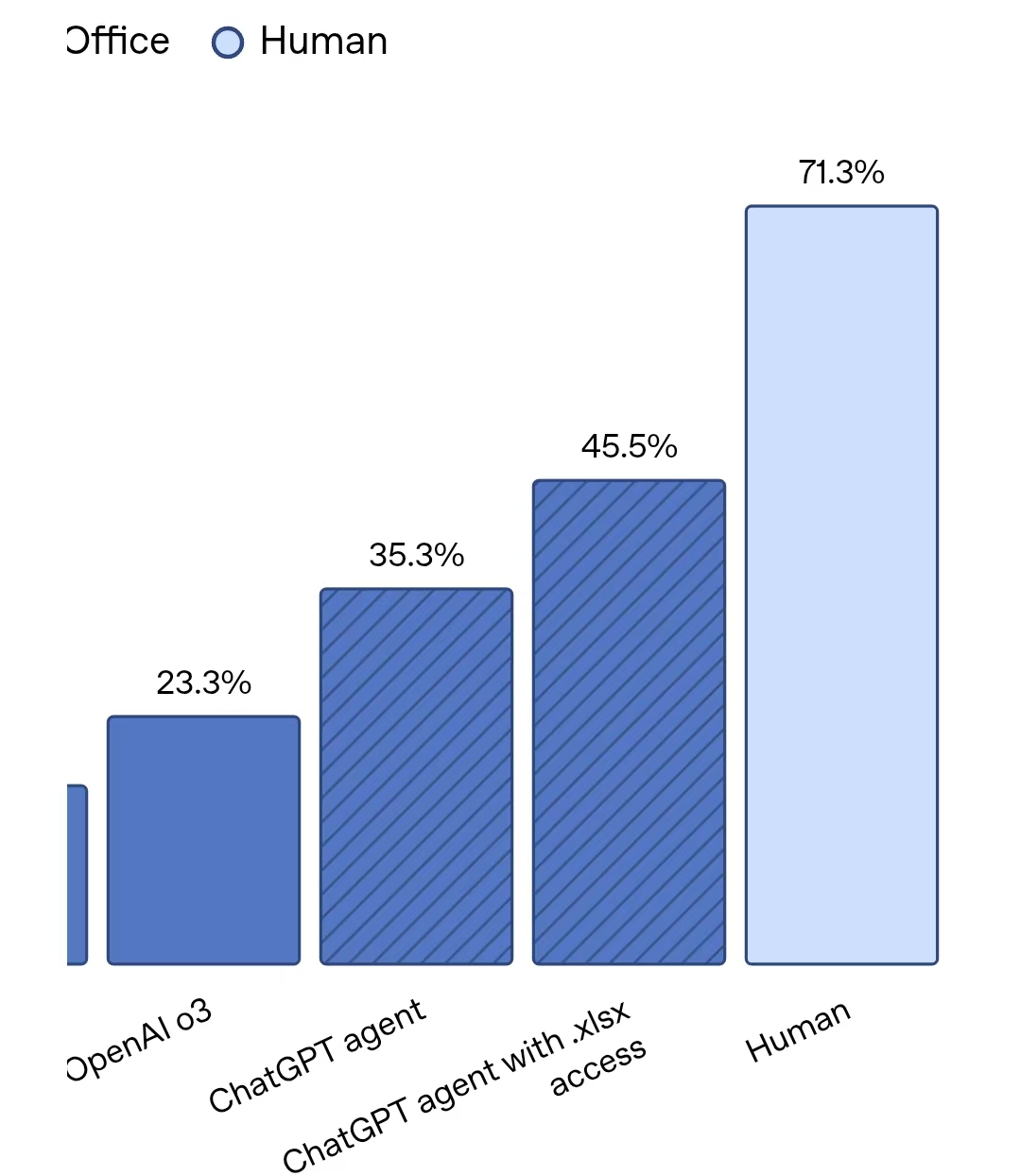
不外,固然ChatGPT Agent在SpreadsheetBench测试(评估模子裁剪着实场景电子表格的智力)中,发挥朝上OpenAI的其他模子,但其最高得分45.5%曾经远低于东谈主类得分71.3%。
OpenAI称,这次更新是一个开动,公司将接续依期迭代篡改。
Agent的智力很猛进程上取决于基础模子的智力。发布ChatGPT Agent后,OpenAI最受怜惜的更新曾经推出GPT-5。此前OpenAI CEO奥尔特曼示意,GPT-5可能于本年夏天推出,OpenAI代表此前曾经闪现,初步展望的发布时辰是在本年7月。刻下,濒临来自DeepSeek等厂商的竞争,OpenAI曾经需要通过推出新的基础模子来解释自己的伊始地位。
从Agent演进上看,有Agent开拓者告诉记者,本年Agent展望不错在数十步较复杂的器用调用中,作念到90%的准确率,基本达到可商用状况。但基础模子的智力曾经还有所欠缺,基础模子还难以作念到自主调用上万个器用并自主实行。
举报 第一财经告白联贯,请点击这里此本体为第一财经原创,文章权归第一财经所有。未经第一财经籍面授权,不得以任何样子加以使用,包括转载、摘编、复制或开拓镜像。第一财经保留讲求侵权者法律职守的权益。如需获取授权请关系第一财经版权部:banquan@yicai.com 文章作家
郑栩彤
关系阅读 OpenAI发布ChatGPT Agent
OpenAI发布ChatGPT AgentChatGPT Agent可将多种智力交融,酿成协调的智能体系统。
121 5小时前 AI进化速递丨首个AI智能体安全测试圭臬发布
AI进化速递丨首个AI智能体安全测试圭臬发布①首个AI智能体安全测试圭臬发布;②浙江大学与阿里巴巴建树AI安全联结子验室;③马斯克称拼凑特斯拉投资xAI举行鼓励投票。
54 07-14 20:44 “高考志愿填报诱骗师”半个月可拿证,用好AI 器用比速成内行靠谱
“高考志愿填报诱骗师”半个月可拿证,用好AI 器用比速成内行靠谱AI在志愿填报中究竟能饰演什么脚色?它的决议依据是什么?鸿沟又在那处?
161 06-25 15:04 爆发前夕的智能体,落在中国算力的舒心区 | 海斌访谈
爆发前夕的智能体,落在中国算力的舒心区 | 海斌访谈AI的发展又来到了一个拐点,“咱们正处在Agentic AI爆发的前夕。”
371 06-21 16:15 盘前必读丨荣耀、中国迁徙完满AI终局计策联贯;GPT-5迎来新音问
盘前必读丨荣耀、中国迁徙完满AI终局计策联贯;GPT-5迎来新音问机构指出,商场需要量能的放大以激活东谈主气买球下单平台,若后续量能放大能有明显的标的聚焦,则3400点的整数关隘有望遏止。
7 505 06-20 07:23 一财最热 点击关闭